Conceitos introdutórios da ferramenta e suas aplicações

Desenvolver serviços que são utilizados por milhões de usuários com tráfego na escala de milhões é uma responsabilidade muito grande. Acompanhar a saúde, comportamento e tendências de aplicação e infraestrutura é uma atividade essencial dentro do iFood. Utilizamos algumas ferramentas para nos auxiliar nesta tarefa, e uma delas é o Prometheus — uma solução de monitoramento e alerta de código aberto.
Neste texto, apresentarei conceitos introdutórios da ferramenta, seus principais componentes, modelos de dados e tipos de estatísticas e dicas de utilização.
Base de dados de métricas e séries temporais
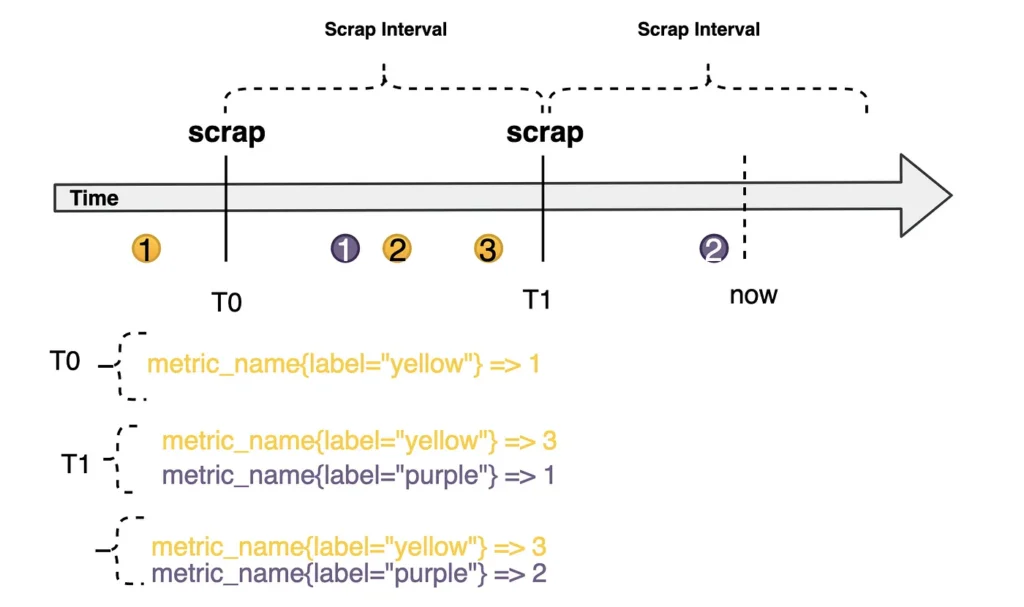
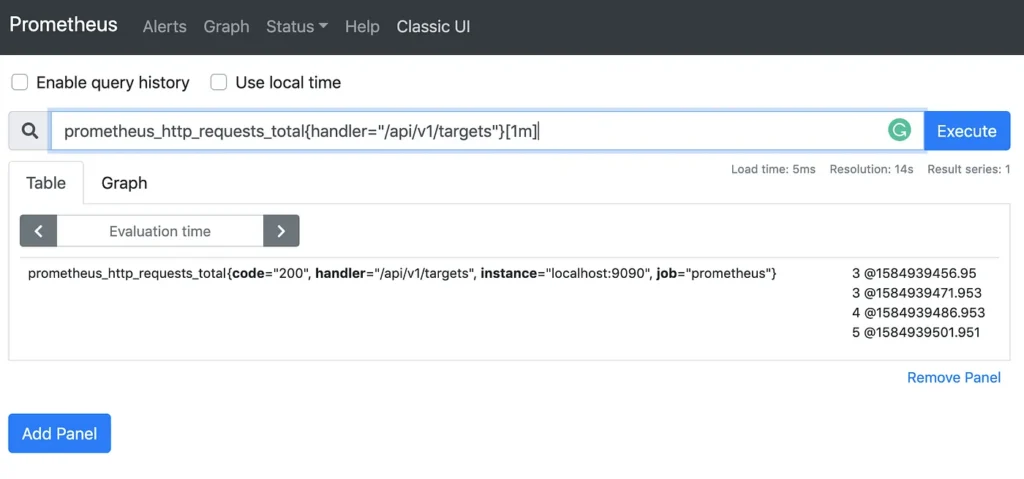
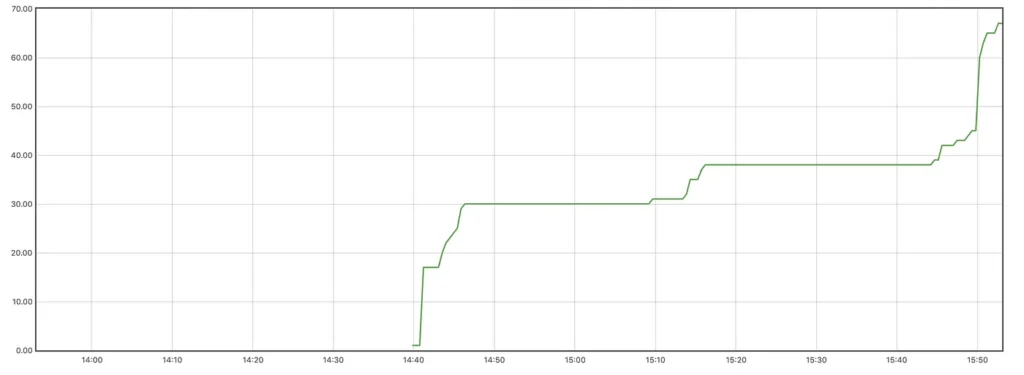
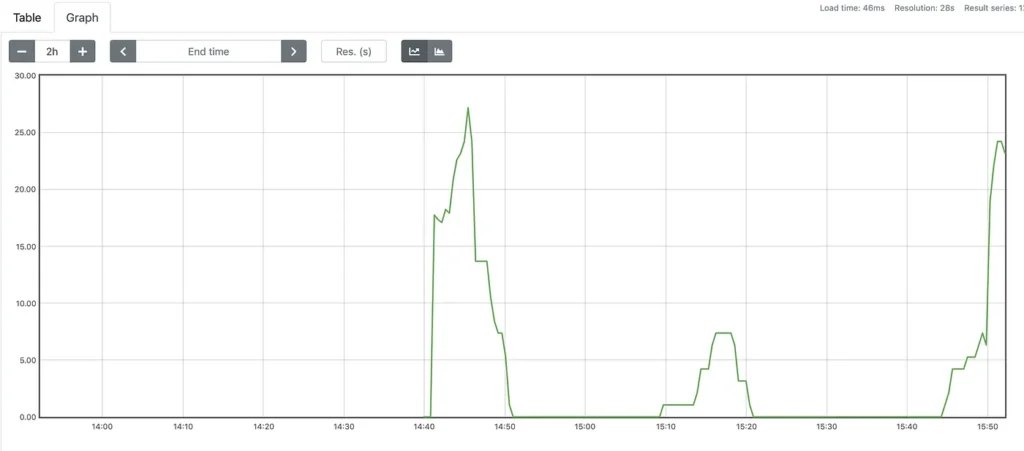
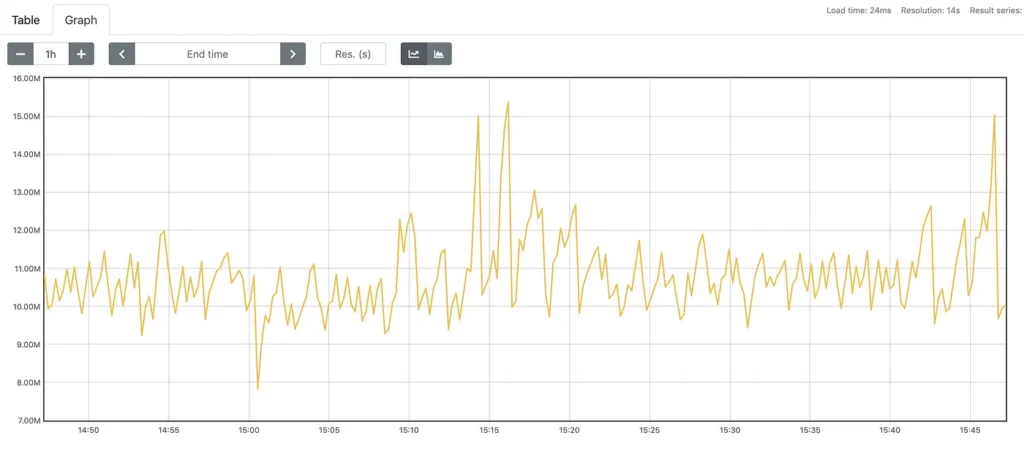
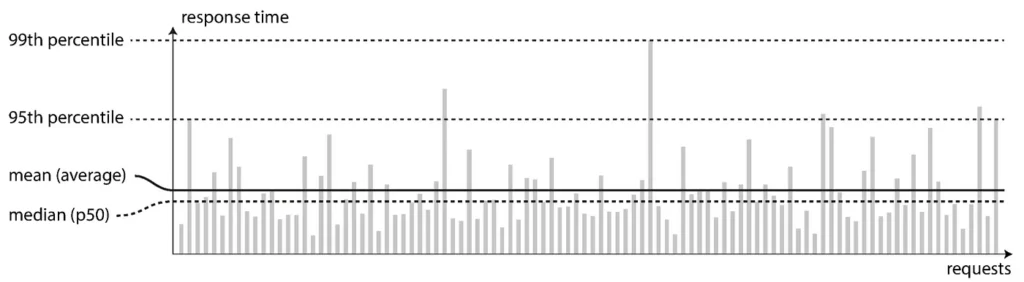
Um ponto que acreditar ser interessante é como as estatísticas são representadas. As coleções armazenadas em uma série temporal base podem ser vistas como fluxos de valores em um momento do tempo . A representação pode ser vista como um identificador , um conjunto de rótulos para definir dimensões. Os registros dessa métrica são um fluxo de valores chamados de amostras.