A revolução digital trouxe desafios e oportunidades para o mundo das entregas de alimentos. Emergindo como uma Food Tech líder na América Latina, o iFood tem constantemente se adaptado à crescente demanda. Mas, com mais usuários e parcerias, veio uma responsabilidade aprimorada: assegurar uma experiência de usuário impecável.

A prevenção às fraudes é crucial no ecossistema das Food Techs. Como uma empresa que processa milhões de pedidos diariamente, o iFood se tornou um alvo atraente para fraudadores, especialmente para os que realizam testes com cartões roubados ou gerados. As tentativas de fraude não só prejudicam a integridade financeira da plataforma, mas também comprometem a confiança dos clientes e dos estabelecimentos parceiros. Em resposta a essa ameaça persistente, o iFood desenvolveu uma abordagem estratégica que combina mecanismos tradicionais de segurança com modelos avançados de inteligência artificial. Esses modelos são treinados para reconhecer padrões suspeitos e avaliar, entre diversos parâmetros, o risco de estornos futuros de transações. Dessa forma, cada pedido não é apenas uma transação, mas também uma verificação contínua da legitimidade, garantindo a segurança de todos os envolvidos no processo.
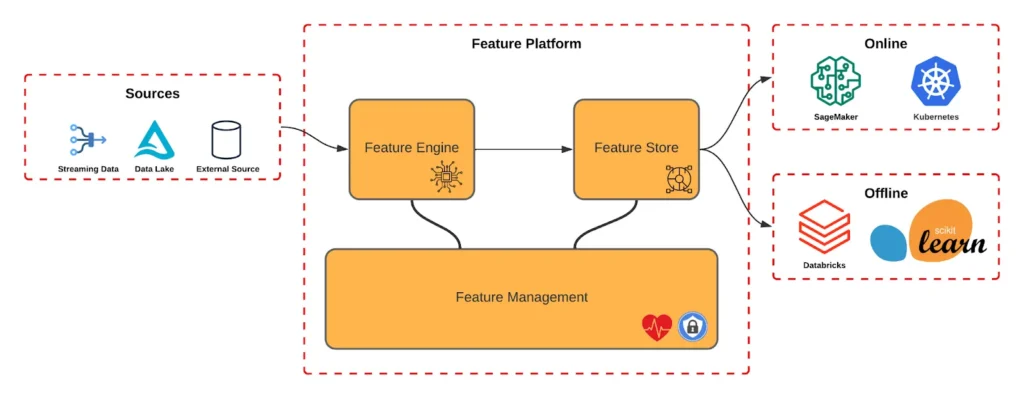
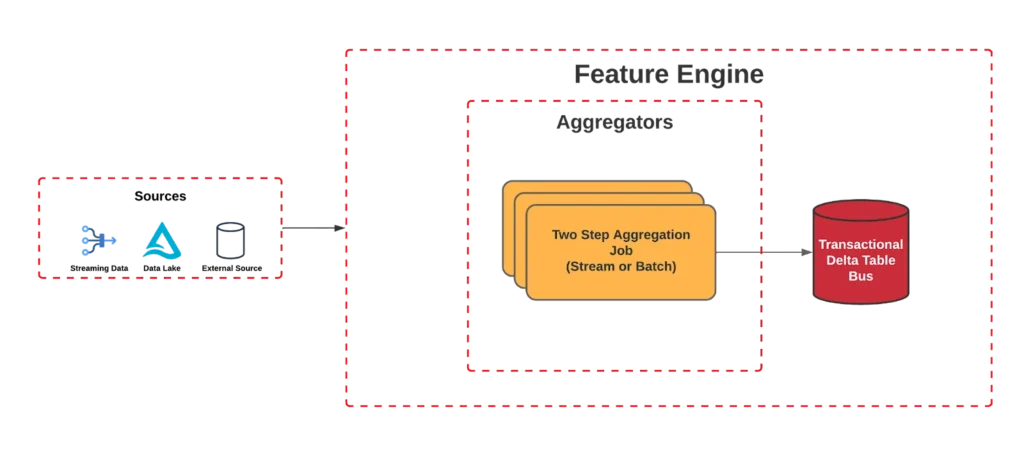
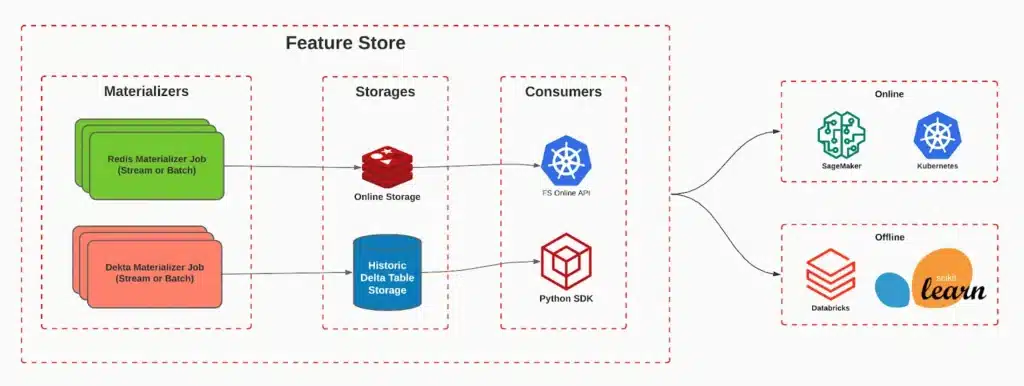
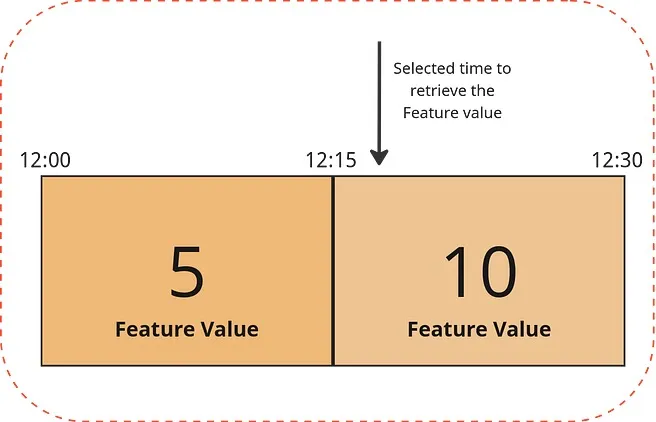
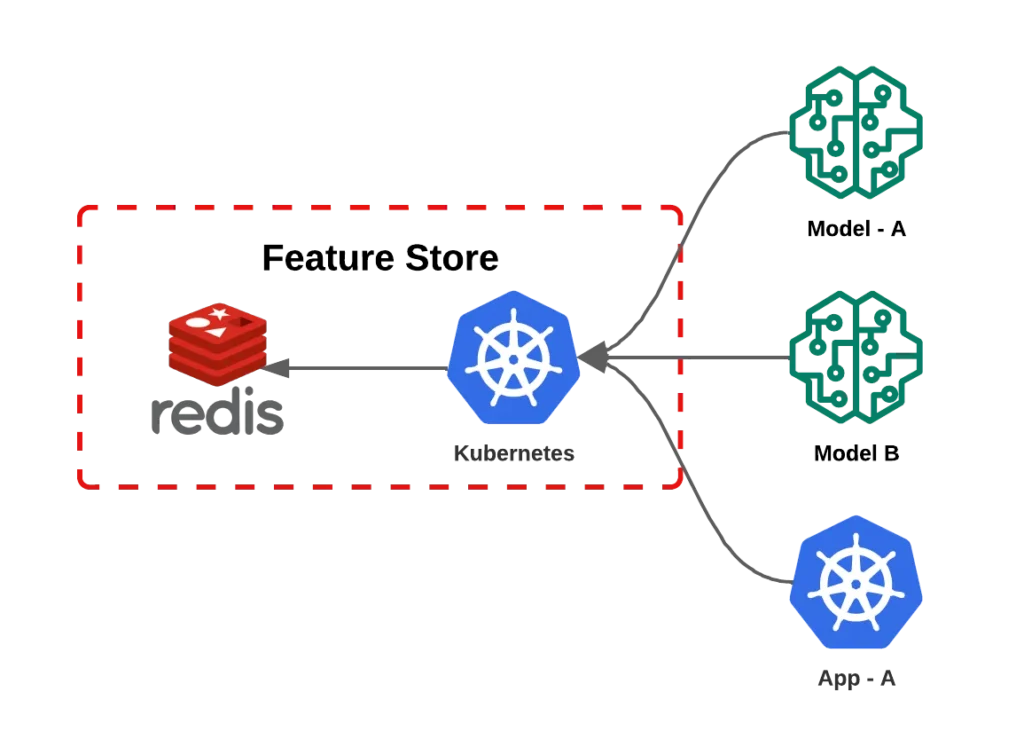
Contudo, gerir esses modelos é uma tarefa muito complexa. Um dos principais desafios enfrentados é manter as características (features) dos modelos atualizadas e assegurar a integridade e a baixa latência no acesso aos dados. E é aqui que entra a inovação do iFood: a Plataforma de Features. Esta solução foi projetada para simplificar a vida dos Cientistas de Dados. Enquanto eles definem ‘o quê’, a plataforma gerencia ‘como’, assegurando a coerência de dados e promovendo uma colaboração eficaz entre equipes. Apoiada pela infraestrutura da AWS, a Plataforma de Features não apenas aborda os desafios intrínsecos da gestão de modelos, mas também permite que a equipe do iFood se concentre no que faz de melhor: oferecer uma experiência superior aos seus clientes.
1. Reusabilidade: Com uma Plataforma de Features, cientistas de dados e engenheiros de ML não precisam recriar ou reprocessar features sempre que desenvolvem um novo modelo. As features existentes podem ser acessadas e compartilhadas por diferentes modelos, economizando tempo e recursos.
2. Consistência: Garante que todas as equipes estejam usando as mesmas definições e transformações de features. Isso é vital para garantir que os insights e previsões gerados por diferentes modelos sejam consistentes e confiáveis.
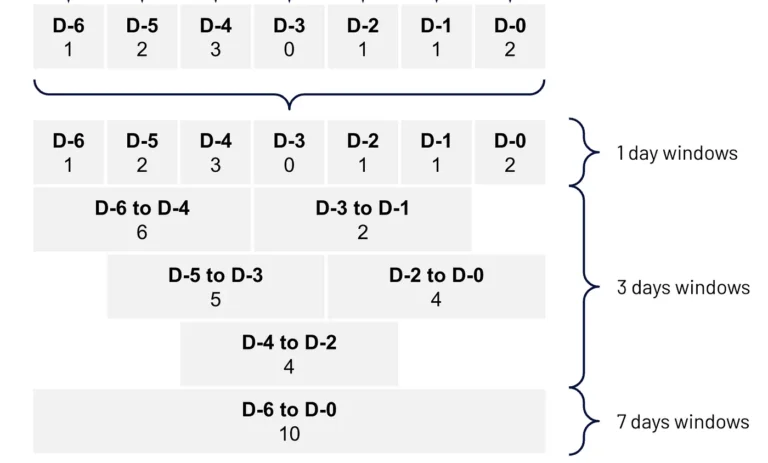
3. Eficiência: Reduz a complexidade ao gerenciar o ciclo de vida das features, desde a criação até o deployment. Também reduz a latência, pois as features necessárias para a inferência em tempo real estão prontamente disponíveis.
4. Escalabilidade: A plataforma é otimizada para lidar com altos volumes de dados, garantindo a construção eficaz de features.
5. Monitoramento/Governança: Oferece total transparência no cálculo das features, registrando fontes, filtros, agregação e mantendo histórico de alterações.