
Willian Moreira
💻 Machine Learning Engineer at iFood
The digital revolution has brought challenges and opportunities to the world of food delivery. Emerging as a leading Food Tech in Latin America, iFood has constantly adapted to growing demand. But with more users and partnerships comes an enhanced responsibility: ensuring a flawless user experience.
Fraud prevention is crucial in the Food Tech ecosystem. As a company that processes millions of orders daily, iFood has become an attractive target for fraudsters, especially those testing stolen or generated cards. Fraud attempts not only harm the financial integrity of the platform, but also compromise the trust of customers and partner establishments. In response to this persistent threat, iFood has developed a strategic approach that combines traditional security mechanisms with advanced artificial intelligence models. These models are trained to recognize suspicious patterns and assess, among several parameters, the risk of future transaction chargebacks. This way, each order is not just a transaction, but also a continuous verification of legitimacy, ensuring the safety of everyone involved in the process.
However, managing these models is a very complex task. One of the main challenges faced is maintaining the characteristics (features) of updated models and ensure integrity and low latency when accessing data. And this is where iFood's innovation comes in: the Features. This solution is designed to simplify the lives of Data Scientists. While they define 'what', the platform manages 'how', ensuring data coherence and promoting effective collaboration between teams. Powered by the AWS infrastructure, the Features not only addresses the intrinsic challenges of model management, but also allows the iFood team to focus on what they do best: delivering a superior experience to their customers.
What is a Features Platform?
A platform for Features is essentially a centralized system that facilitates the management and use of features of ML across the organization. Features are the individual inputs (or variables) that feed an ML model. Once these features are created, they need to be stored, managed, and retrieved efficiently for model training and inference.
1. Reusability: With a Platform Features, data scientists and ML engineers do not need to recreate or reprocess features whenever they develop a new model. Existing features can be accessed and shared across different models, saving time and resources.
2. Consistency: Ensures that all teams are using the same definitions and transformations features. This is vital to ensure that the insights and predictions generated by different models are consistent and reliable.
3. Efficiency: Reduces complexity when managing the lifecycle of features, from creation to deployment. It also reduces latency, as features needed for real-time inference are readily available.
4. Scalability: The platform is optimized to handle high volumes of data, ensuring effective construction of features.
5. Monitoring/Governance: Offers complete transparency in the calculation of features, recording sources, filters, aggregation and maintaining change history.
Proposed solution
Fraud detection models are vital, particularly in scenarios where response time is essential, as is the case with iFood. The challenge lies not only in operating a critical model in real time, but also in the demands imposed on the productization of features, an aspect that, in itself, constitutes a major engineering challenge. The requirement is for quick and consistent responses, which prompted iFood to develop the Features.
Before the platform, the average fraud system response time was 250 ms. With the implementation of the platform, this time was reduced to 50 ms, showing a significant improvement in the system's response. The platform not only simplified the creation and management of features, but also ensured consistency by tackling the problem of differences between feature logic executed in a training pipeline and feature logic for inference (feature skew), a critical issue in the productization of fraud detection models.
Developed mainly to process features in real time, the Platform Features integrates tools such as Apache Spark, Apache Kafka, Delta Lake and Redis, this combination guarantees maximum performance, regardless of data volume, establishing a new standard of efficiency and effectiveness in fraud detection and prevention. This robust infrastructure not only accelerates the detection of fraudulent activity, but also provides a more agile and flexible environment for data scientists, facilitating continuous innovation and improvement of fraud models.
How does the Features Platform drive innovation at iFood?
The routine of a data science team is full of complex steps, for example, managing pipelines data, engineering features, real-time model monitoring, etc. One of the most laborious phases is the operationalization of features; establish a robust infrastructure to build and test features It is, without a doubt, a challenge. This is where the Platform Features stands out, providing agility for teams. The platform not only optimizes processes, but also brings with it a series of benefits, such as:
– Agility in Model Development: The Platform Features allows iFood data scientists to focus on experimenting and optimizing models, rather than spending time on productizing features.
– Continuous Integration and Delivery (CI/CD) for Features: The descriptive nature of features facilitates continuous integration and delivery, allowing updates to be implemented faster and more fluidly.
– Improved Collaboration: With a centralized repository, teams can collaborate better, sharing insights and improvements in features.
– Fast and Reliable Delivery: The platform not only stores features, but also ensures that they are delivered effectively and in real time to models in production. This is crucial for low latency models.
How does the Features Platform work?
The platform features is composed of three main abstractions: Feature Engine, The Feature Store and the Feature Management, as can be seen in Image 1. Each layer is responsible for ensuring the necessary steps to deliver the features as quickly as possible ensuring security, resilience and simplicity.
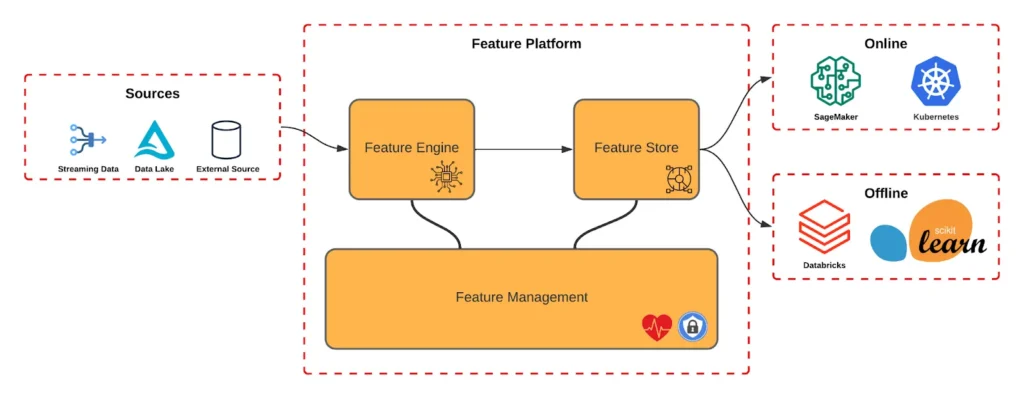
Feature Engine
This layer consists of the abstraction of the entire platform aggregation engine. The aggregation process is critical for transforming large volumes of data into meaningful information that can be used for analysis, reporting and decision making.
We also note that in the development of features Data Scientists often use several features similar, only varying the window, for example, order count from the last 7, 30 and 60 days. That's why we developed what we call two-step aggregation, as can be seen in image 2.
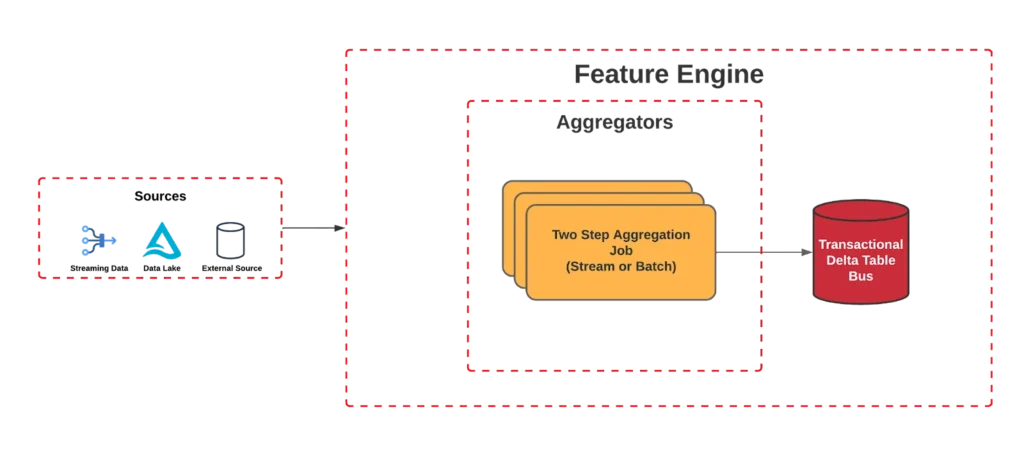
O Two Step Aggregator internally organizes the data into smaller windows that we call step. For example, if the ultimate goal is to aggregate a month's worth of data, the step It could be one day. This approach allows the results of these small segments to be stored as intermediate states, which are essentially partial results that will be used to create any larger windows.
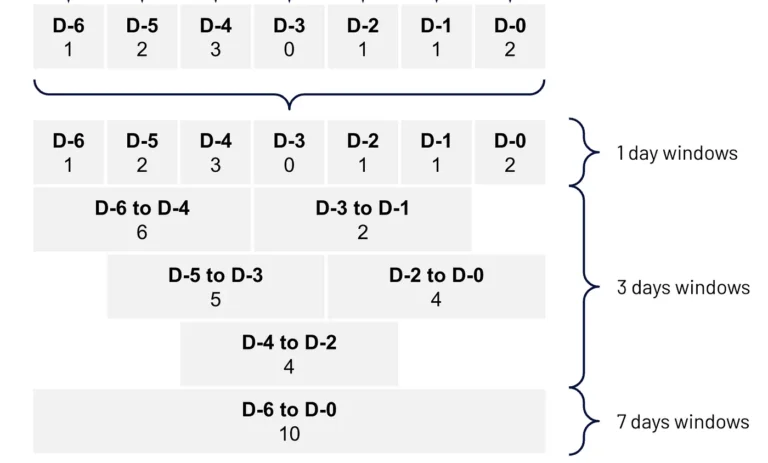
Once the intermediate states are stored, we combine these results to produce the final aggregation. For example, the results from each daily “window step” would be combined to produce the aggregate result for the month. This step offers some benefits, for example, there is a reduction in costs, as it allows us to have several windows being processed in the same Spark query execution, something that native Spark does not support today, requiring a query dedicated to each window.
Furthermore, the platform has streaming as its main focus, and with this we are able to use the same code base to process both batch and streaming data. In other words, everything that works in streaming also works in batch processing.
Finally, each update of the feature is stored in a Delta Table located in an S3 bucket. The data is structured in a transactional format, which means that every time a change is made to the feature, a new entry is recorded in this table. This facilitates the reconstruction of any database at subsequent times, acting in a similar way to a database transactional log.
Feature Store
The Feature Store is a central component that serves as a repository for features. features processed and ready for use in machine learning models.
The main advantage of the Feature Store is its ability to reuse and share features between different models and applications, providing consistency and minimizing the need for rework.
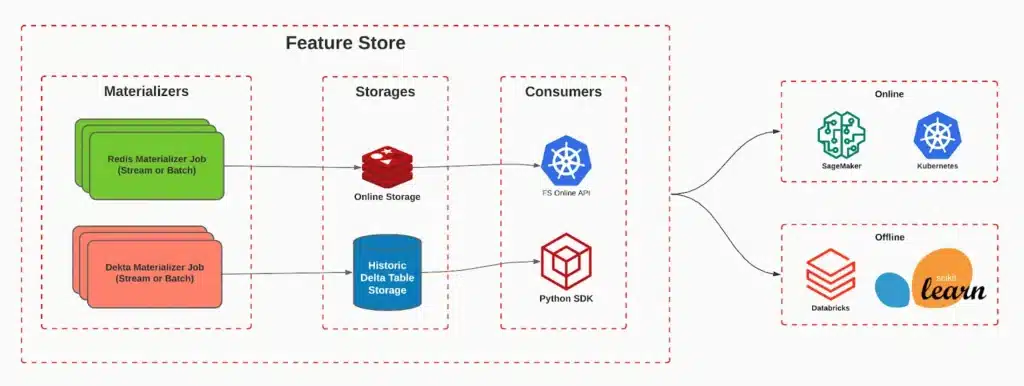
The Feature Store can be segmented into two categories, meeting different needs:
Online Storage
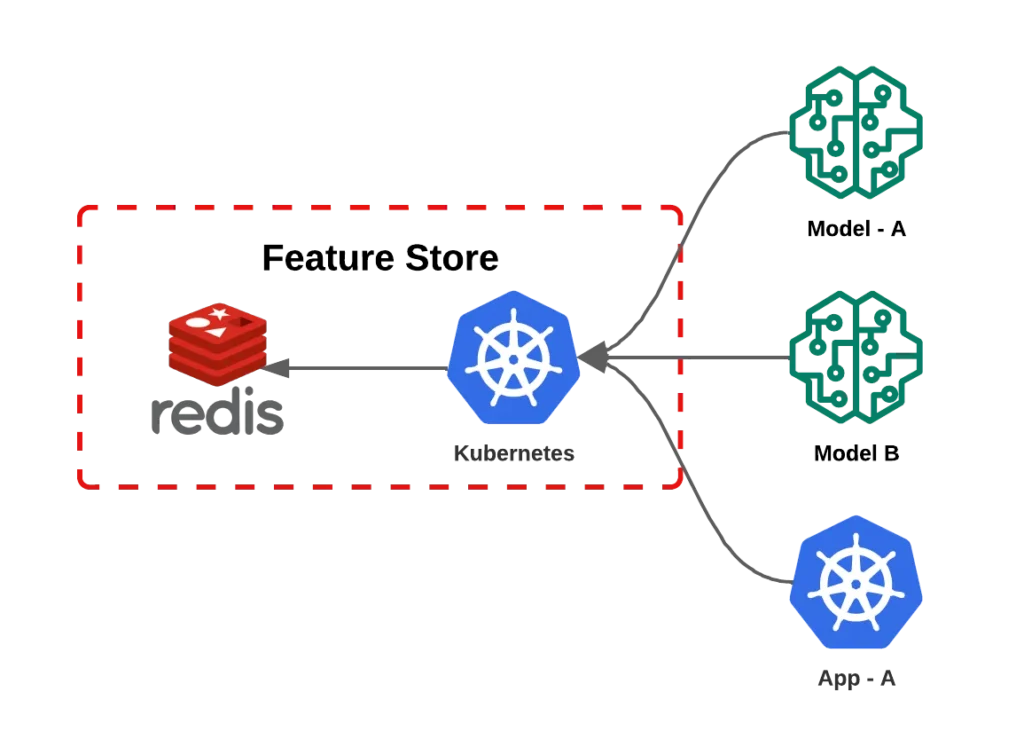
Online storage is designed to be fast and efficient. It is optimized for low-latency queries, making it ideal for real-time applications. At iFood we store the features in Redis, thus achieving latencies of less than 10 milliseconds for recovering data features, even with a high volume of requests.
Main Features:
- Low Latency: We serve features in less than 10 milliseconds
- Scalability: By combining Redis with a Kubernetes application, we effortlessly achieved rates of 3 million requests per minute. This solution is very flexible and scalable, as in times of low flow unnecessary resources are displaced, resulting in cost optimization.
Usage Examples:
- Recommendations for dishes and restaurants;
- Segmentations;
- Fraud detection.
Offline Storage
Offline storage, on the other hand, is optimized for capacity and durability. In addition to allowing you to store large volumes of data for long periods of time, it also makes it possible to “travel in time”, that is, it makes it possible to retrieve values of a feature at a certain point in time, necessary for model training. For this we use the Delta Table for our offline storage, this gives us great flexibility, mainly because we have the possibility of using both streaming and batches to update it.
Main Features:
- Large Capacity: Can store terabytes or even petabytes of data.
- Durability: Based on AWS S3, it guarantees security and resistance to failures.
- Time travel: Allows you to access features at certain points in time efficiently.
Usage Examples:
- Machine learning model training: Models are trained using large datasets for better accuracy.
- Historical analysis: Allows analysis of trends over time.
- Batch inference, enabling offline models to perform batch processing efficiently without impacting the online flow.
For each type of storage, we use what we call 'materializers'. These are in charge of reading transactions from the Delta Table and storing them in the appropriate destination. For online storage, we have 'Redis Materializer', which is responsible for saving only the most recent version of the feature in a Redis for fast recovery. On the other hand, the 'Delta Materializer' is responsible for ensuring the consistency of the history, storing it in a Delta Table.
Feature Management
The Feature Engine layer is responsible for calculating the feature, the Feature Store layer is responsible for storing and serving the features consistently, but still has a range of services and applications that are necessary to keep the entire platform healthy and secure. To achieve this, we introduced the Feature Management layer, which guarantees the integrity, efficiency and security of the platform. features, acting as a guardian to ensure that features are generated, stored and accessed appropriately. One of the vital functions of Feature Management is continuous monitoring, which is crucial to maintaining the health of the feature management platform. features. Through it, it is possible to identify problems before they affect end users, optimize the platform's performance and receive real-time notifications about any irregularities or failures.
In addition to monitoring, Feature Management is responsible for managing the life cycle of features. This involves determining which features can be deleted, identify which ones are frequently accessed and by whom, in addition to monitoring costs and warning about features that are not being used. This layer also provides tools to change or delete features as necessary.
Versioning is another crucial function, allowing you to track and manage different versions of features, maintaining a history of all changes and ensuring that models and applications are using the correct version of features. In addition to keeping records of all operations carried out, allowing you to track who accessed or modified features. In summary, Feature Management is fundamental to ensuring that the features function optimally and securely, meeting users’ needs.
How the platform solved problems to combat fraud.
While our fraud models already take advantage of Amazon SageMaker, ensuring scalability and resilience, we faced internal challenges related to creating and maintaining features. These costly processes resulted in significant latencies, in addition to the other problems mentioned. But how does the team actually use the features in your routine?
The platform provides an SDK that provides facilitating mechanisms for recovering features both for training through dataset enrichment, and for inference where it offers an interface for retrieving the latest values of features
During training, our focus is to extract historical data using a unique identifier and a precise moment in time. To ensure that future information is not exposed, we adopt a closed time window approach. This means that the moment chosen for analysis must always be after the end of this window. For example, if we select a period after 12:15, we get the value 5. If we choose a time after 12:30, the value will be 10, and so on, as illustrated in image 5.
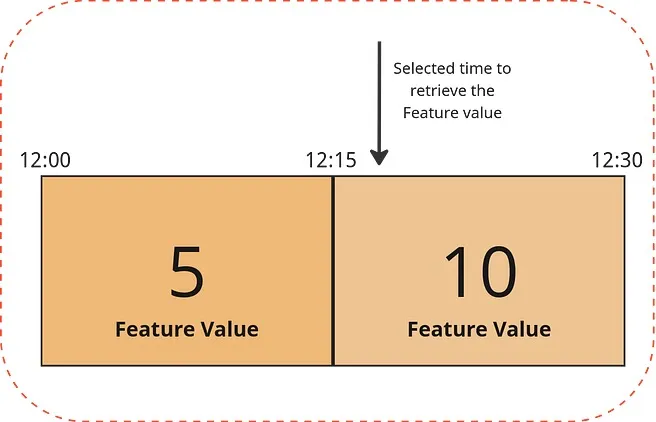
The end product of this process is a Spark dataframe, where each characteristic is converted into a distinct column. Our platform ensures the correct aggregation of data at the appropriate time, eliminating risks such as future data leaks or data inconsistencies.
In the context of training, data accuracy is our main concern, without the need to focus on latency. However, during the inference phase, latency plays a crucial role. To meet this demand, we offer a REST API specialized in recovering features, which is highly scalable and capable of processing millions of requests per minute. During inference, we only need the identifier to access the most recent data. With this, each model accesses the features through the API retrieving all features necessary for its inference stage and then makes its prediction.
With this approach, we achieved a significant improvement in the inference efficiency of our models, reducing latency in data recovery. features from 250ms to 50ms. This optimization not only makes it possible for scientists to explore new possibilities, but also guarantees an exceptional experience for iFood users.
Conclusion
The adoption of the Platform Features was crucial for the iFood fraud team. Replacing manual and time-consuming processes, the team now has an automated and optimized solution. This platform has not only simplified the management of features, but also addressed and resolved latency issues, reducing latency by approximately five times.
In addition to impacting processing speed, the platform also boosted collaboration and efficiency within the team. When treating features as code and offer a standardized library, the reuse and discovery of features between teams. This has enabled data scientists to focus their efforts on creating and optimizing models, accelerating innovation.
The platform Features, by reducing operational load and improving latency, raised the fraud team's performance standard. However, the benefits were not restricted to this team alone. Today, the platform serves more than a billion requests daily, covering more than 800 features, and is used by teams such as recommendations, logistics, marketing, among others, consolidating its value in iFood.


